59. Poll Mode Driver for Emulated Virtio NIC
Virtio is a para-virtualization framework initiated by IBM, and supported by KVM hypervisor. In the Data Plane Development Kit (DPDK), we provide a virtio Poll Mode Driver (PMD) as a software solution, comparing to SRIOV hardware solution, for fast guest VM to guest VM communication and guest VM to host communication.
Vhost is a kernel acceleration module for virtio qemu backend.
For basic qemu-KVM installation and other Intel EM poll mode driver in guest VM, please refer to Chapter “Driver for VM Emulated Devices”.
In this chapter, we will demonstrate usage of virtio PMD with two backends, standard qemu vhost back end.
59.1. Virtio Implementation in DPDK
For details about the virtio spec, refer to the latest VIRTIO (Virtual I/O) Device Specification.
As a PMD, virtio provides packet reception and transmission callbacks.
In Rx, packets described by the used descriptors in vring are available for virtio to burst out.
In Tx, packets described by the used descriptors in vring are available for virtio to clean. Virtio will enqueue to be transmitted packets into vring, make them available to the device, and then notify the host back end if necessary.
59.2. Features and Limitations of virtio PMD
In this release, the virtio PMD provides the basic functionality of packet reception and transmission.
- It supports merge-able buffers per packet when receiving packets and scattered buffer per packet when transmitting packets. The packet size supported is from 64 to 9728.
- It supports multicast packets and promiscuous mode.
- The descriptor number for the Rx/Tx queue is hard-coded to be 256 by qemu 2.7 and below. If given a different descriptor number by the upper application, the virtio PMD generates a warning and fall back to the hard-coded value. Rx queue size can be configurable and up to 1024 since qemu 2.8 and above. Rx queue size is 256 by default. Tx queue size is still hard-coded to be 256.
- Features of mac/vlan filter are supported, negotiation with vhost/backend are needed to support them. When backend can’t support vlan filter, virtio app on guest should not enable vlan filter in order to make sure the virtio port is configured correctly. E.g. do not specify ‘–enable-hw-vlan’ in testpmd command line. Note that, mac/vlan filter is best effort: unwanted packets could still arrive.
- “RTE_PKTMBUF_HEADROOM” should be defined no less than “sizeof(struct virtio_net_hdr_mrg_rxbuf)”, which is 12 bytes when mergeable or “VIRTIO_F_VERSION_1” is set. no less than “sizeof(struct virtio_net_hdr)”, which is 10 bytes, when using non-mergeable.
- Virtio does not support runtime configuration.
- Virtio supports Link State interrupt.
- Virtio supports Rx interrupt (so far, only support 1:1 mapping for queue/interrupt).
- Virtio supports software vlan stripping and inserting.
- Virtio supports using port IO to get PCI resource when UIO module is not available.
- Virtio supports RSS Rx mode with 40B configurable hash key length, 128 configurable RETA entries and configurable hash types.
59.3. Prerequisites
The following prerequisites apply:
- In the BIOS, turn VT-x and VT-d on
- Linux kernel with KVM module; vhost module loaded and ioeventfd supported. Qemu standard backend without vhost support isn’t tested, and probably isn’t supported.
- When using legacy interface,
SYS_RAWIOcapability is required foriopl()call to enable access to PCI I/O ports.
59.4. Virtio with qemu virtio Back End
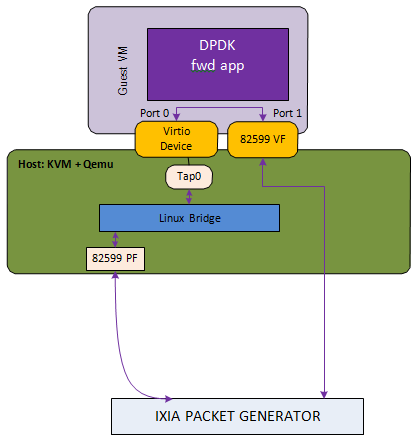
Fig. 59.1 Host2VM Communication Example Using qemu vhost Back End
qemu-system-x86_64 -enable-kvm -cpu host -m 2048 -smp 2 -mem-path /dev/
hugepages -mem-prealloc
-drive file=/data/DPDKVMS/dpdk-vm1
-netdev tap,id=vm1_p1,ifname=tap0,script=no,vhost=on
-device virtio-net-pci,netdev=vm1_p1,bus=pci.0,addr=0x3,ioeventfd=on
-device pci-assign,host=04:10.1 \
In this example, the packet reception flow path is:
IXIA packet generator->82599 PF->Linux Bridge->TAP0’s socket queue-> Guest VM virtio port 0 Rx burst-> Guest VM 82599 VF port1 Tx burst-> IXIA packet generator
The packet transmission flow is:
IXIA packet generator-> Guest VM 82599 VF port1 Rx burst-> Guest VM virtio port 0 Tx burst-> tap -> Linux Bridge->82599 PF-> IXIA packet generator
59.5. Virtio PMD Rx/Tx Callbacks
Virtio driver has 6 Rx callbacks and 3 Tx callbacks.
Rx callbacks:
virtio_recv_pkts: Regular version without mergeable Rx buffer support for split virtqueue.virtio_recv_mergeable_pkts: Regular version with mergeable Rx buffer support for split virtqueue.virtio_recv_pkts_vec: Vector version without mergeable Rx buffer support, also fixes the available ring indexes and uses vector instructions to optimize performance for split virtqueue.virtio_recv_pkts_inorder: In-order version with mergeable and non-mergeable Rx buffer support for split virtqueue.virtio_recv_pkts_packed: Regular and in-order version without mergeable Rx buffer support for packed virtqueue.virtio_recv_mergeable_pkts_packed: Regular and in-order version with mergeable Rx buffer support for packed virtqueue.
Tx callbacks:
virtio_xmit_pkts: Regular version for split virtqueue.virtio_xmit_pkts_inorder: In-order version for split virtqueue.virtio_xmit_pkts_packed: Regular and in-order version for packed virtqueue.
By default, the non-vector callbacks are used:
- For Rx: If mergeable Rx buffers is disabled then
virtio_recv_pktsorvirtio_recv_pkts_packedwill be used, otherwisevirtio_recv_mergeable_pktsorvirtio_recv_mergeable_pkts_packedwill be used. - For Tx:
virtio_xmit_pktsorvirtio_xmit_pkts_packedwill be used.
Vector callbacks will be used when:
- Mergeable Rx buffers is disabled.
The corresponding callbacks are:
- For Rx:
virtio_recv_pkts_vec.
There is no vector callbacks for packed virtqueue for now.
Example of using the vector version of the virtio poll mode driver in
testpmd:
dpdk-testpmd -l 0-2 -n 4 -- -i --rxq=1 --txq=1 --nb-cores=1
In-order callbacks only work on simulated virtio user vdev.
For split virtqueue:
- For Rx: If in-order is enabled then
virtio_recv_pkts_inorderis used. - For Tx: If in-order is enabled then
virtio_xmit_pkts_inorderis used.
For packed virtqueue, the default callbacks already support the in-order feature.
59.6. Interrupt mode
There are three kinds of interrupts from a virtio device over PCI bus: config interrupt, Rx interrupts, and Tx interrupts. Config interrupt is used for notification of device configuration changes, especially link status (lsc). Interrupt mode is translated into Rx interrupts in the context of DPDK.
Note
Virtio PMD already has support for receiving lsc from qemu when the link status changes, especially when vhost user disconnects. However, it fails to do that if the VM is created by qemu 2.6.2 or below, since the capability to detect vhost user disconnection is introduced in qemu 2.7.0.
59.6.1. Prerequisites for Rx interrupts
To support Rx interrupts,
Check if guest kernel supports VFIO-NOIOMMU:
Linux started to support VFIO-NOIOMMU since 4.8.0. Make sure the guest kernel is compiled with:
CONFIG_VFIO_NOIOMMU=yProperly set msix vectors when starting VM:
Enable multi-queue when starting VM, and specify msix vectors in qemu cmdline. (N+1) is the minimum, and (2N+2) is mostly recommended.
$(QEMU) ... -device virtio-net-pci,mq=on,vectors=2N+2 ...
In VM, insert vfio module in NOIOMMU mode:
modprobe vfio enable_unsafe_noiommu_mode=1 modprobe vfio-pci
In VM, bind the virtio device with vfio-pci:
./usertools/dpdk-devbind.py -b vfio-pci 00:03.0
59.6.2. Example
Here we use l3fwd-power as an example to show how to get started.
Example:
$ dpdk-l3fwd-power -l 0-1 -- -p 1 -P --config="(0,0,1)" \ --no-numa --parse-ptype
59.7. Runtime Configuration
Below devargs are supported by the PCI virtio driver:
vdpa:A virtio device could also be driven by vDPA (vhost data path acceleration) driver, and works as a HW vhost backend. This argument is used to specify a virtio device needs to work in vDPA mode. (Default: 0 (disabled))
speed:It is used to specify link speed of virtio device. Link speed is a part of link status structure. It could be requested by application using rte_eth_link_get_nowait function. (Default: 0xffffffff (Unknown))
vectorized:It is used to specify whether virtio device prefers to use vectorized path. Afterwards, dependencies of vectorized path will be checked in path election. (Default: 0 (disabled))
Below devargs are supported by the virtio-user vdev:
path:It is used to specify a path to connect to vhost backend.
mac:It is used to specify the MAC address.
cq:It is used to enable the control queue. (Default: 0 (disabled))
queue_size:It is used to specify the queue size. (Default: 256)
queues:It is used to specify the queue number. (Default: 1)
iface:It is used to specify the host interface name for vhost-kernel backend.
server:It is used to enable the server mode when using vhost-user backend. (Default: 0 (disabled))
mrg_rxbuf:It is used to enable virtio device mergeable Rx buffer feature. (Default: 1 (enabled))
in_order:It is used to enable virtio device in-order feature. (Default: 1 (enabled))
packed_vq:It is used to enable virtio device packed virtqueue feature. (Default: 0 (disabled))
speed:It is used to specify link speed of virtio device. Link speed is a part of link status structure. It could be requested by application using rte_eth_link_get_nowait function. (Default: 0xffffffff (Unknown))
vectorized:It is used to specify whether virtio device prefers to use vectorized path. Afterwards, dependencies of vectorized path will be checked in path election. (Default: 0 (disabled))
59.8. Virtio paths Selection and Usage
Logically virtio-PMD has 9 paths based on the combination of virtio features (Rx mergeable, In-order, Packed virtqueue), below is an introduction of these features:
- Rx mergeable: With this feature negotiated, device can receive large packets by combining individual descriptors.
- In-order: Some devices always use descriptors in the same order in which they have been made available, these devices can offer the VIRTIO_F_IN_ORDER feature. With this feature negotiated, driver will use descriptors in order.
- Packed virtqueue: The structure of packed virtqueue is different from split virtqueue, split virtqueue is composed of available ring, used ring and descriptor table, while packed virtqueue is composed of descriptor ring, driver event suppression and device event suppression. The idea behind this is to improve performance by avoiding cache misses and make it easier for hardware to implement.
59.8.1. Virtio paths Selection
If packed virtqueue is not negotiated, below split virtqueue paths will be selected according to below configuration:
- Split virtqueue mergeable path: If Rx mergeable is negotiated, in-order feature is not negotiated, this path will be selected.
- Split virtqueue non-mergeable path: If Rx mergeable and in-order feature are not negotiated, also Rx offload(s) are requested, this path will be selected.
- Split virtqueue in-order mergeable path: If Rx mergeable and in-order feature are both negotiated, this path will be selected.
- Split virtqueue in-order non-mergeable path: If in-order feature is negotiated and Rx mergeable is not negotiated, this path will be selected.
- Split virtqueue vectorized Rx path: If Rx mergeable is disabled and no Rx offload requested, this path will be selected.
If packed virtqueue is negotiated, below packed virtqueue paths will be selected according to below configuration:
- Packed virtqueue mergeable path: If Rx mergeable is negotiated, in-order feature is not negotiated, this path will be selected.
- Packed virtqueue non-mergeable path: If Rx mergeable and in-order feature are not negotiated, this path will be selected.
- Packed virtqueue in-order mergeable path: If in-order and Rx mergeable feature are both negotiated, this path will be selected.
- Packed virtqueue in-order non-mergeable path: If in-order feature is negotiated and Rx mergeable is not negotiated, this path will be selected.
- Packed virtqueue vectorized Rx path: If building and running environment support (AVX512 || NEON) && in-order feature is negotiated && Rx mergeable is not negotiated && TCP_LRO Rx offloading is disabled && vectorized option enabled, this path will be selected.
- Packed virtqueue vectorized Tx path: If building and running environment support (AVX512 || NEON) && in-order feature is negotiated && vectorized option enabled, this path will be selected.
59.8.2. Rx/Tx callbacks of each Virtio path
Refer to above description, virtio path and corresponding Rx/Tx callbacks will be selected automatically. Rx callbacks and Tx callbacks for each virtio path are shown in below table:
| Virtio paths | Rx callbacks | Tx callbacks |
|---|---|---|
| Split virtqueue mergeable path | virtio_recv_mergeable_pkts | virtio_xmit_pkts |
| Split virtqueue non-mergeable path | virtio_recv_pkts | virtio_xmit_pkts |
| Split virtqueue in-order mergeable path | virtio_recv_pkts_inorder | virtio_xmit_pkts_inorder |
| Split virtqueue in-order non-mergeable path | virtio_recv_pkts_inorder | virtio_xmit_pkts_inorder |
| Split virtqueue vectorized Rx path | virtio_recv_pkts_vec | virtio_xmit_pkts |
| Packed virtqueue mergeable path | virtio_recv_mergeable_pkts_packed | virtio_xmit_pkts_packed |
| Packed virtqueue non-mergeable path | virtio_recv_pkts_packed | virtio_xmit_pkts_packed |
| Packed virtqueue in-order mergeable path | virtio_recv_mergeable_pkts_packed | virtio_xmit_pkts_packed |
| Packed virtqueue in-order non-mergeable path | virtio_recv_pkts_packed | virtio_xmit_pkts_packed |
| Packed virtqueue vectorized Rx path | virtio_recv_pkts_packed_vec | virtio_xmit_pkts_packed |
| Packed virtqueue vectorized Tx path | virtio_recv_pkts_packed | virtio_xmit_pkts_packed_vec |
59.8.3. Virtio paths Support Status from Release to Release
Virtio feature implementation:
- In-order feature is supported since DPDK 18.08 by adding new Rx/Tx callbacks
virtio_recv_pkts_inorderandvirtio_xmit_pkts_inorder. - Packed virtqueue is supported since DPDK 19.02 by adding new Rx/Tx callbacks
virtio_recv_pkts_packed,virtio_recv_mergeable_pkts_packedandvirtio_xmit_pkts_packed.
All virtio paths support status are shown in below table:
| Virtio paths | 16.11 ~ 18.05 | 18.08 ~ 18.11 | 19.02 ~ 19.11 | 20.05 ~ |
|---|---|---|---|---|
| Split virtqueue mergeable path | Y | Y | Y | Y |
| Split virtqueue non-mergeable path | Y | Y | Y | Y |
| Split virtqueue vectorized Rx path | Y | Y | Y | Y |
| Split virtqueue simple Tx path | Y | N | N | N |
| Split virtqueue in-order mergeable path | Y | Y | Y | |
| Split virtqueue in-order non-mergeable path | Y | Y | Y | |
| Packed virtqueue mergeable path | Y | Y | ||
| Packed virtqueue non-mergeable path | Y | Y | ||
| Packed virtqueue in-order mergeable path | Y | Y | ||
| Packed virtqueue in-order non-mergeable path | Y | Y | ||
| Packed virtqueue vectorized Rx path | Y | |||
| Packed virtqueue vectorized Tx path | Y |
59.8.4. QEMU Support Status
- Qemu now supports three paths of split virtqueue: Split virtqueue mergeable path, Split virtqueue non-mergeable path, Split virtqueue vectorized Rx path.
- Since qemu 4.2.0, Packed virtqueue mergeable path and Packed virtqueue non-mergeable path can be supported.
59.8.5. How to Debug
If you meet performance drop or some other issues after upgrading the driver or configuration, below steps can help you identify which path you selected and root cause faster.
- Run vhost/virtio test case;
- Run “perf top” and check virtio Rx/Tx callback names;
- Identify which virtio path is selected refer to above table.