36. LPM6 Library
The LPM6 (LPM for IPv6) library component implements the Longest Prefix Match (LPM) table search method for 128-bit keys that is typically used to find the best match route in IPv6 forwarding applications.
36.1. LPM6 API Overview
The main configuration parameters for the LPM6 library are:
- Maximum number of rules: This defines the size of the table that holds the rules, and therefore the maximum number of rules that can be added.
- Number of tbl8s: A tbl8 is a node of the trie that the LPM6 algorithm is based on.
This parameter is related to the number of rules you can have, but there is no way to accurately predict the number needed to hold a specific number of rules, since it strongly depends on the depth and IP address of every rule. One tbl8 consumes 1 kb of memory. As a recommendation, 65536 tbl8s should be sufficient to store several thousand IPv6 rules, but the number can vary depending on the case.
An LPM prefix is represented by a pair of parameters (128-bit key, depth), with depth in the range of 1 to 128. An LPM rule is represented by an LPM prefix and some user data associated with the prefix. The prefix serves as the unique identifier for the LPM rule. In this implementation, the user data is 21-bits long and is called “next hop”, which corresponds to its main use of storing the ID of the next hop in a routing table entry.
The main methods exported for the LPM component are:
- Add LPM rule: The LPM rule is provided as input. If there is no rule with the same prefix present in the table, then the new rule is added to the LPM table. If a rule with the same prefix is already present in the table, the next hop of the rule is updated. An error is returned when there is no available space left.
- Delete LPM rule: The prefix of the LPM rule is provided as input. If a rule with the specified prefix is present in the LPM table, then it is removed.
- Lookup LPM key: The 128-bit key is provided as input. The algorithm selects the rule that represents the best match for the given key and returns the next hop of that rule. In the case that there are multiple rules present in the LPM table that have the same 128-bit value, the algorithm picks the rule with the highest depth as the best match rule, which means the rule has the highest number of most significant bits matching between the input key and the rule key.
36.1.1. Implementation Details
This is a modification of the algorithm used for IPv4 (see Implementation Details). In this case, instead of using two levels, one with a tbl24 and a second with a tbl8, 14 levels are used.
The implementation can be seen as a multi-bit trie where the stride or number of bits inspected on each level varies from level to level. Specifically, 24 bits are inspected on the root node, and the remaining 104 bits are inspected in groups of 8 bits. This effectively means that the trie has 14 levels at the most, depending on the rules that are added to the table.
The algorithm allows the lookup operation to be performed with a number of memory accesses that directly depends on the length of the rule and whether there are other rules with bigger depths and the same key in the data structure. It can vary from 1 to 14 memory accesses, with 5 being the average value for the lengths that are most commonly used in IPv6.
The main data structure is built using the following elements:
- A table with 2^24 entries
- A number of tables, configurable by the user through the API, with 2^8 entries
The first table, called tbl24, is indexed using the first 24 bits of the IP address be looked up, while the rest of the tables, called tbl8s, are indexed using the rest of the bytes of the IP address, in chunks of 8 bits. This means that depending on the outcome of trying to match the IP address of an incoming packet to the rule stored in the tbl24 or the subsequent tbl8s we might need to continue the lookup process in deeper levels of the tree.
Similar to the limitation presented in the algorithm for IPv4, to store every possible IPv6 rule, we would need a table with 2^128 entries. This is not feasible due to resource restrictions.
By splitting the process in different tables/levels and limiting the number of tbl8s, we can greatly reduce memory consumption while maintaining a very good lookup speed (one memory access per level).
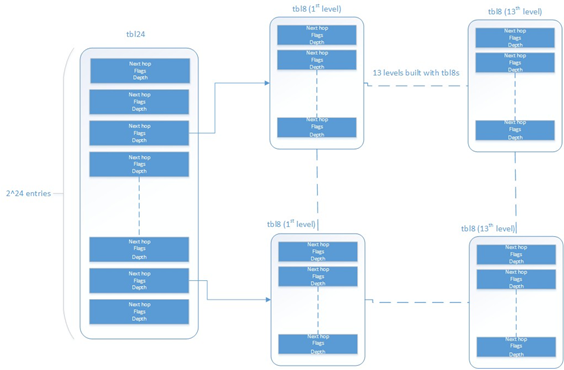
Fig. 36.1 Table split into different levels
An entry in a table contains the following fields:
- next hop / index to the tbl8
- depth of the rule (length)
- valid flag
- valid group flag
- external entry flag
The first field can either contain a number indicating the tbl8 in which the lookup process should continue or the next hop itself if the longest prefix match has already been found. The depth or length of the rule is the number of bits of the rule that is stored in a specific entry. The flags are used to determine whether the entry/table is valid or not and whether the search process have finished or not respectively.
Both types of tables share the same structure.
The other main data structure is a table containing the main information about the rules (IP, next hop and depth). This is a higher level table, used for different things:
- Check whether a rule already exists or not, prior to addition or deletion, without having to actually perform a lookup.
When deleting, to check whether there is a rule containing the one that is to be deleted. This is important, since the main data structure will have to be updated accordingly.
36.1.2. Addition
When adding a rule, there are different possibilities. If the rule’s depth is exactly 24 bits, then:
- Use the rule (IP address) as an index to the tbl24.
- If the entry is invalid (i.e. it doesn’t already contain a rule) then set its next hop to its value, the valid flag to 1 (meaning this entry is in use), and the external entry flag to 0 (meaning the lookup process ends at this point, since this is the longest prefix that matches).
If the rule’s depth is bigger than 24 bits but a multiple of 8, then:
- Use the first 24 bits of the rule as an index to the tbl24.
- If the entry is invalid (i.e. it doesn’t already contain a rule) then look for a free tbl8, set the index to the tbl8 to this value, the valid flag to 1 (meaning this entry is in use), and the external entry flag to 1 (meaning the lookup process must continue since the rule hasn’t been explored completely).
- Use the following 8 bits of the rule as an index to the next tbl8.
- Repeat the process until the tbl8 at the right level (depending on the depth) has been reached and fill it with the next hop, setting the next entry flag to 0.
If the rule’s depth is any other value, prefix expansion must be performed. This means the rule is copied to all the entries (as long as they are not in use) which would also cause a match.
As a simple example, let’s assume the depth is 20 bits. This means that there are 2^(24-20) = 16 different combinations of the first 24 bits of an IP address that would cause a match. Hence, in this case, we copy the exact same entry to every position indexed by one of these combinations.
By doing this we ensure that during the lookup process, if a rule matching the IP address exists, it is found in, at the most, 14 memory accesses, depending on how many times we need to move to the next table. Prefix expansion is one of the keys of this algorithm, since it improves the speed dramatically by adding redundancy.
Prefix expansion can be performed at any level. So, for example, is the depth is 34 bits, it will be performed in the third level (second tbl8-based level).
36.1.3. Lookup
The lookup process is much simpler and quicker. In this case:
- Use the first 24 bits of the IP address as an index to the tbl24. If the entry is not in use, then it means we don’t have a rule matching this IP. If it is valid and the external entry flag is set to 0, then the next hop is returned.
- If it is valid and the external entry flag is set to 1, then we use the tbl8 index to find out the tbl8 to be checked, and the next 8 bits of the IP address as an index to this table. Similarly, if the entry is not in use, then we don’t have a rule matching this IP address. If it is valid then check the external entry flag for a new tbl8 to be inspected.
- Repeat the process until either we find an invalid entry (lookup miss) or a valid entry with the external entry flag set to 0. Return the next hop in the latter case.
36.1.4. Limitations in the Number of Rules
There are different things that limit the number of rules that can be added. The first one is the maximum number of rules, which is a parameter passed through the API. Once this number is reached, it is not possible to add any more rules to the routing table unless one or more are removed.
The second limitation is in the number of tbl8s available. If we exhaust tbl8s, we won’t be able to add any more rules. How to know how many of them are necessary for a specific routing table is hard to determine in advance.
In this algorithm, the maximum number of tbl8s a single rule can consume is 13, which is the number of levels minus one, since the first three bytes are resolved in the tbl24. However:
- Typically, on IPv6, routes are not longer than 48 bits, which means rules usually take up to 3 tbl8s.
As explained in the LPM for IPv4 algorithm, it is possible and very likely that several rules will share one or more tbl8s, depending on what their first bytes are. If they share the same first 24 bits, for instance, the tbl8 at the second level will be shared. This might happen again in deeper levels, so, effectively, two 48 bit-long rules may use the same three tbl8s if the only difference is in their last byte.
The number of tbl8s is a parameter exposed to the user through the API in this version of the algorithm, due to its impact in memory consumption and the number or rules that can be added to the LPM table. One tbl8 consumes 1 kilobyte of memory.
36.2. Use Case: IPv6 Forwarding
The LPM algorithm is used to implement the Classless Inter-Domain Routing (CIDR) strategy used by routers implementing IP forwarding.