By Antanoly Burakov
This post is Part 2 of a 4-part blog series that was originally published on the Intel Developer Zone blog.
Introduction
In the previous article, we covered the main concepts and principles behind Data Plane Development Kit (DPDK) memory management and how they contribute to DPDK’s unparalleled performance. However, DPDK is a complex beast that needs to be configured correctly to make the most out of it. In particular, picking the right kernel driver and IOVA mode may be crucial, depending on the application, as well as the environment in which said application is intended to run. This article discusses various options available and makes recommendations on what should be used.
Environment Abstraction Layer (EAL) Parameters
At the heart of DPDK lies the Environment Abstraction Layer (EAL). The EAL is a DPDK library that, as its name suggests, abstracts away the environment (hardware, OS, and so on) and presents a unified interface to software. EAL handles a great many things and is easily the single most complex part of DPDK. Some of the things EAL is responsible for include:
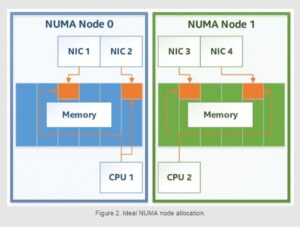
- Managing CPU cores and non-uniform memory access (NUMA) nodes
- Making hardware devices available to DPDK poll-mode drivers (PMDs) by mapping their registers into memory
- Managing hardware and software interrupts
- Abstracting away platform differences such as endianness, cache line size, and so on
- Managing memory and multiprocess synchronization
- Providing platform- and OS-independent ways of working with atomics, memory barriers, and other synchronization primitives
- Loading and enumerating hardware buses, devices, and PMDs
The above list is by no means exhaustive, but it gives an idea of how vital the EAL is to DPDK. It is therefore no surprise that a lot of configuration in DPDK has to do with configuring the EAL. Currently, this is (directly or indirectly) done through specifying command-line parameters to the DPDK initialization routine. Usually, a DPDK application command-line would look like the following:

Some applications using DPDK may hide this step from the user (such as OvS-DPDK), so there may be no need to specify EAL command-line parameters explicitly, but it is nevertheless always happening in the background.
IO Virtual Addresses (IOVA) Modes
DPDK is a user space application framework, so software using DPDK works with regular virtual addresses, like any other software. However, DPDK also provides user space PMDs and a set of APIs to perform IO operations entirely from user space. As was discussed in the previous article in this series, the hardware does not understand user space virtual addresses; instead, it uses IO addresses—either physical addresses (PA), or IO virtual addresses (IOVA).
The DPDK API does not distinguish between physical and IO virtual addresses, and always refers to either as IOVA, even if no IO memory management unit (IOMMU) is involved to provide the VA part. However, DPDK does distinguish between cases where physical addresses are used as IOVA, and cases where IOVA matches user space virtual addresses. These cases are referred to as IOVA modes in the DPDK API, and there are two of them: IOVA as PA, and IOVA as VA.
IOVA as Physical Addresses (PA) Mode
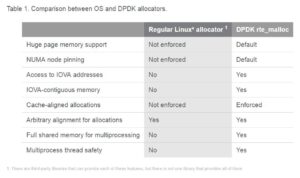
When IOVA as PA mode is used, the IOVA addresses assigned to all DPDK memory areas are actual physical addresses, and virtual memory layout matches the physical memory layout. The good thing about this approach is that it is simple: it works with all hardware (that is, does not require IOMMU), and it works well with kernel space (it is trivial to convert a real physical address to a kernel space address). This is in fact how DPDK has worked for a long time, and it is in many ways considered the default.
There are certain disadvantages associated with using IOVA as PA mode, however. One of them is that it requires privileges—DPDK cannot get a memory region’s real physical address without having access to the system’s page map. Thus, it is not possible to run in IOVA as PA mode without root privileges on the system.
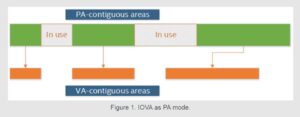
Another notable limitation of IOVA as PA mode is that virtual memory layout follows physical memory layout. This means that if physical memory space is fragmented (that is, there are lots of small segments instead of a few large ones), the virtual memory space follows that fragmentation. In extreme cases, the fragmentation can be so severe that the number of standalone, physically contiguous segments exhausts DPDK’s internal data structures used to store information about those segments, and DPDK initialization simply fails.
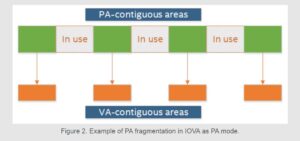
The DPDK community has come up with workarounds to address these issues. For example, one way to reduce the impact of fragmentation is to use bigger page sizes—the problem is not fixed, but a standalone 1-gigabyte (GB) segment is way more useful than a standalone 2-megabyte (MB) segment. Rebooting the system and reserving huge pages at boot time instead of at run time is another widely used workaround. None of the above workarounds fix the underlying problem though, and the DPDK community is so used to dealing with it that every DPDK user (knowingly or unknowingly) ends up following the same thought process of “I need X MB of memory, but I’ll reserve X+Y MB just in case!”
IOVA as Virtual Addresses (VA) Mode
IOVA as VA mode, in contrast, is a mode in which the underlying physical memory layout is not followed. Instead, the physical memory is reshuffled in such a way as to match the virtual memory layout. DPDK EAL does so by relying on kernel infrastructure, which in turn uses IOMMU to remap physical memory.
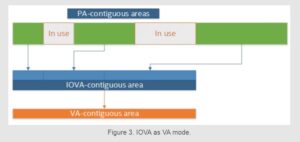
The advantage of this approach is obvious: in the case of IOVA as VA mode, all memory is both VA- and IOVA-contiguous. This means that any memory allocation that requires lots of IOVA-contiguous memory is more likely to succeed because the memory looks IOVA-contiguous to the hardware, even though the underlying physical memory may not be. Because of the remapping, the problem of fragmented IOVA space becomes irrelevant; however heavily fragmented the physical memory can be, it is always remapped to appear as an IOVA-contiguous chunk of memory.
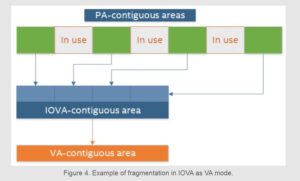
Another advantage of using IOVA as VA mode is that it does not require any privileges, because it does not need access to the system page map. This allows running DPDK as a non-root user, and makes it easier to use DPDK in environments where privileged access is undesirable, such as cloud-native environments.
There is of course one disadvantage to using IOVA as VA mode. For various reasons, using the IOMMU may not be an option. Such circumstances may include:
- Hardware that does not support using IOMMU
- Platform may not have an IOMMU in the first place (for example, a VM without IOMMU emulation)
- Software devices (for example, DPDK’s Kernel Network Interface (KNI) PMD) will not support IOVA as VA mode
- Some IOMMUs (generally emulated ones) may have a limited address width, which, while not preventing the use of IOVA as VA mode, limits its usefulness
- Using DPDK on an OS other than Linux*
However, such cases are relatively rare, and in the great majority of scenarios, IOVA as VA mode will work just fine.
Which IOVA Mode to Use
In many cases, DPDK chooses IOVA as PA mode as the default, as it is the most safe mode to use from the hardware perspective. Any given hardware (or software) PMD is all but guaranteed to support at least IOVA as PA mode. Nevertheless, all DPDK users are highly encouraged to use IOVA as VA mode whenever possible, as there are undeniable advantages to using this mode.
The user, however, does not have to pick one over the other. The most suitable IOVA mode is detected automatically, and the default value most definitely works for the majority of cases, so no user interaction is required to make this choice. If the default is not suitable, the user can attempt to override the IOVA mode with an EAL flag (applicable to DPDK 17.11 and later) by using the –iova-mode EAL command-line parameter:

In most cases, VA and PA modes do not exclude each other and either one can be used, but there are some circumstances where IOVA as PA mode will be the only available option. If using IOVA as VA mode is not available, DPDK automatically switches over to IOVA as PA mode, even if it was requested to use IOVA as VA mode through an EAL parameter.
DPDK also provides an API to query which particular IOVA mode is in use at run time, but generally it is not used in user applications, as such information is usually only required by entities like DPDK PMDs and bus drivers.
IOVA Mode and DPDK PCI Drivers
DPDK does not do all hardware device register and interrupt mapping by itself; it needs a little help from the kernel. To accomplish that, all hardware devices that are to be used by DPDK need to be bound to a generic Peripheral Component Interconnect (PCI) kernel driver. The generic part means that this driver is not locked to a specific set of PCI IDs like regular drivers, but can instead be used with any PCI device.
To bind a device to a generic driver, DPDK users are encouraged to refer to DPDK documentation, which describes this process for all supported OSes. However, a few words need to be said about various user space IO drivers supported by DPDK, and which IOVA modes they support. It may seem like there would be a 1:1 correspondence between a kernel driver and supported IOVA modes, but that is not actually the case. The following section discusses available drivers on Linux.
User Space IO (UIO) Drivers
The oldest kernel driver in the DPDK codebase is the igb_uio driver. It has been there pretty much since the beginning of DPDK, and it is thus the most widely used and the most familiar driver to DPDK developers.
This driver relies on kernel user space IO (UIO) infrastructure to work, and provides support for all interrupt types (legacy, message signaled interrupts (MSI), and MSI-X), as well as creating virtual functions. It also exposes hardware devices’ registers and interrupt handles through the /dev/uio file system, which DPDK EAL then uses to map them into user space and make them available for DPDK PMDs.
The igb_uio driver is very simple and does not do very much. It is therefore no surprise that it does not support using IOMMU. Or, to be more precise, it does support IOMMU, but only in pass-through mode, which sets up a 1:1 mapping between IOVA and the physical address. Using full IOMMU mode is not supported by igb_uio. As a consequence, the igb_uio driver only supports IOVA as PA mode and cannot work in IOVA as VA mode at all.
A driver similar to igb_uio is available in the kernel: uio_pci_generic. It works pretty much the same way as igb_uio, except that it is more limited in what it can do. For example, igb_uio supports all interrupt types (legacy, MSI, and MSI-X), while uio_pci_generic only supports legacy interrupts. Perhaps more importantly, igb_uio can also create virtual functions, while uio_pci_generic cannot; so, if creating virtual functions while using a DPDK physical function driver is a requirement, igb_uio is the only option.
Thus, in most cases, igb_uio would be either equivalent or preferable to uio_pci_generic. All of the limitations with regard to using IOMMU apply equally to both igb_uio and uio_pci_generic drivers—they cannot use full IOMMU functionality, and thus only support IOVA as PA mode.
VFIO Kernel Driver
An alternative to the above drivers is a vfio-pci driver. It is part of Virtual Function I/O (VFIO) kernel infrastructure and was introduced in Linux version 3.6. The VFIO infrastructure makes both device registers and device interrupts available to user space applications, and can use the IOMMU to set up IOVA mappings to perform IO from user space. The latter part is crucial—this driver was developed specifically for use with IOMMU and, on older kernels, will not even work without IOMMU enabled.
Contrary to what might seem intuitive, using the VFIO driver allows using both IOVA as PA and IOVA as VA modes. This is because, while it is recommended to use IOVA as VA mode to avail all of the benefits of that mode, nothing stops DPDK’s EAL from setting up IOMMU maps in such a way as to follow the physical memory layout 1:1; the IOVA mappings are arbitrary, after all. In that case, even though the IOMMU is used, DPDK will work in IOVA as PA mode, thereby allowing things like DPDK KNI to work. It does, however, still require root privileges to use IOVA as PA mode.
On more recent kernels (4.5+, backported to some older versions), there is an enable_unsafe_noiommu_mode option available that allows using VFIO without IOMMU. This mode is for all intents and purposes identical to UIO-based drivers, and shares all of the same advantages and limitations they have.
Which Kernel Driver to Use
Generally speaking, it is not a choice that has to be made. More often than not, the situation dictates the appropriate driver to use. The following flowchart is helpful in deciding which driver can be used in a particular circumstance:
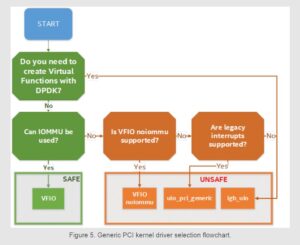
As is clear from Figure 5, it is highly recommended to use the VFIO driver in just about all cases, especially in production environments. Using IOMMU provides device isolation at a hardware level, which makes applications using DPDK more secure, and using IOVA as VA mode allows better use of memory through remapping, as well as not requiring root privileges to run DPDK applications. However, certain use cases will require either igb_uio or uio_pci_generic drivers.
Software Poll Mode Drivers (PMD)
In addition to the above, DPDK also comes with a range of software PMDs that do not require a generic kernel PCI driver, and instead rely on standard kernel infrastructure to provide hardware support. This enables DPDK to work with almost any hardware, even if it is not natively supported by DPDK.
Currently, DPDK has PMDs for the PCAP library, which is a widely used and supported packet capture library for network hardware. DPDK also supports Linux networking with an AF_PACKET PMD, and there is also ongoing work to support AF_XDP natively in DPDK. Using these PMDs comes with a (sometimes considerable) performance cost, but the flipside is that the setup is easy, and these PMDs usually do not care about IOVA mode at all.
Summary
This article provided an in-depth view of how DPDK deals with physical memory, as well as outlined physical addressing features available in DPDK when using various Linux* kernel drivers.
This is the second article in the series of articles about memory management in DPDK. The first article outlined key principles that lie at the foundation of DPDK’s memory management subsystem. The following articles in this series provide a historical perspective on memory management features available in DPDK long term support (LTS) releases 17.11 and earlier, as well as describe the changes and new features available in 18.11 and later DPDK versions.