Authors: Ben Thomas (Linux Foundation Marketing Lead) & Kevin Traynor (LTS Maintainer & Software Engineer @ Redhat)
Navigating the complex landscape of Data Plane Development Kit (DPDK) releases, particularly Long-Term Support (LTS) versions, is often accompanied with pressing questions: “Which release is most suitable for my needs?” “What are the advantages of choosing an LTS release?” “How does an LTS release impact the stability and life span of my network applications?”
This detailed blog aims to shed light on these queries and steer you towards the appropriate DPDK LTS release for your specific requirements.
Understanding DPDK LTS Releases
DPDK is a collection of libraries and drivers that enable rapid packet processing, which is essential in network functions virtualization (NFV), cloud computing, and other high-speed networking environments.
LTS releases are special in that they are designated to receive ongoing maintenance updates, including bug fixes and security patches, for a longer duration than standard releases.
DPDK LTS vs. Standard Releases
DPDK standard releases are known for their rapid development and inclusion of bleeding-edge features. In contrast, LTS releases follow a more systematic and stable approach, focusing on a consistent cadence of fixes and releases.
This distinction is important for organizations deciding between adopting the latest DPDK features or prioritizing long-term stability, who anticipate a solid three-year cycle of maintenance, with security patches often exceeding this period.
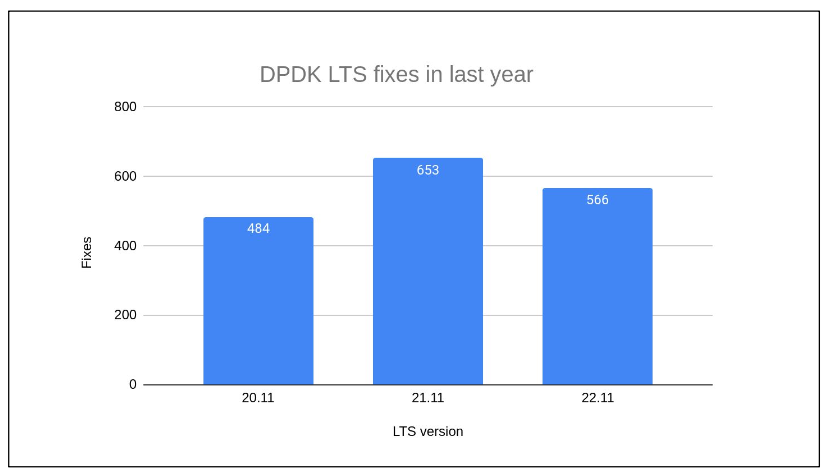
Volume of Fixes in Each Release
A notable characteristic of DPDK LTS releases is the substantial number of fixes each version receives. This high volume of fixes is a testament to the active maintenance and commitment to ensuring the reliability and stability of each LTS version. It indicates the ongoing effort to address a wide range of issues, from minor bugs to critical vulnerabilities.
Simultaneous Maintenance of Multiple Versions
DPDK’s maintenance strategy includes managing three LTS versions simultaneously. This approach ensures that organizations using different versions of DPDK LTS receive the necessary support and updates. It exemplifies the dedication of the DPDK community to cater to a diverse range of users and their varying adoption timelines.
Differences in Fixes Across Versions
The number of fixes in LTS releases varies based on the age and lifecycle of the release. For instance, an older release like 20.11 tends to have fewer fixes as it matures and stabilizes over time. In contrast, a newer release like 22.11, which was released late in 2022, has not yet completed a full year of fixes. This discrepancy in the number of fixes reflects the evolving nature of each release and the continuous effort to enhance stability and performance.
Impact of Release Timelines on Maintenance
The timing of a release plays a critical role in its maintenance cycle. A newer release like 22.11, having been in the market for a shorter duration, might not have accumulated as many fixes as an older release. This variation underscores the importance of understanding the release timelines and their implications on the maintenance and support cycles of DPDK LTS releases.
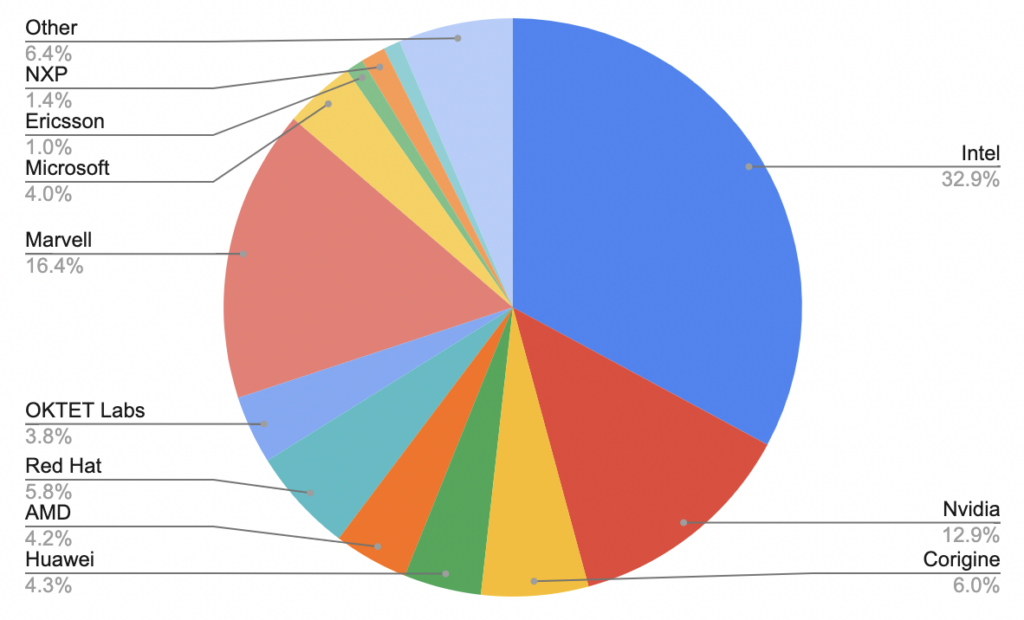
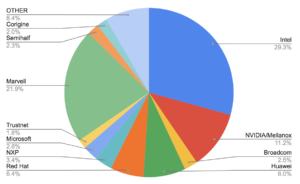
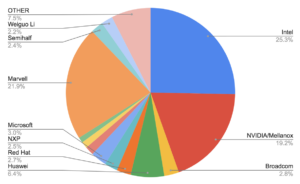
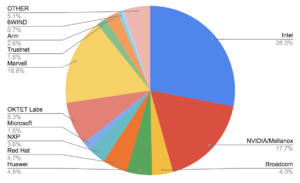
Enhanced Focus on NIC and Driver Fixes in LTS Releases
One of the key aspects of DPDK LTS releases is their focus on Network Interface Controller (NIC) and driver fixes. Hardware vendors are deeply invested in driver functionality, making them some of the most active contributors to the DPDK LTS ecosystem. Their involvement is crucial, as they provide the expertise and timely updates necessary to keep the drivers—and thus the network—running smoothly.
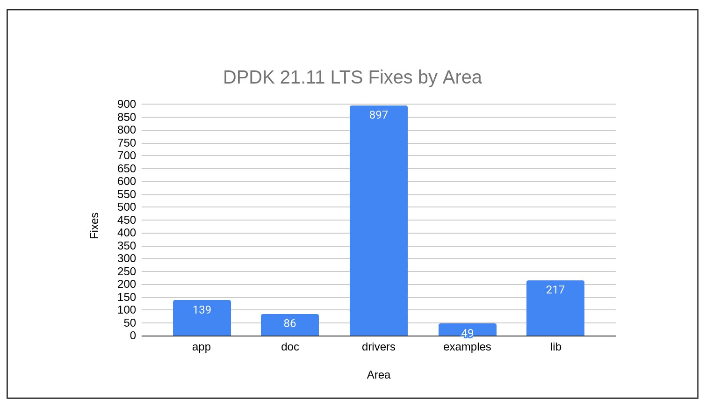
Trends in Bug Fixes and Maintenance
An analysis of recent LTS versions, such as version 22.11.3, reveals a trend of decreasing bug fixes. This trend corresponds to the number of bugs found in the main branch, contrasting with previous versions where fixes averaged around 300. The rate of fixes is not fixed; as a release ages, the number of fixes tends to decrease, indicating increased stability over time.
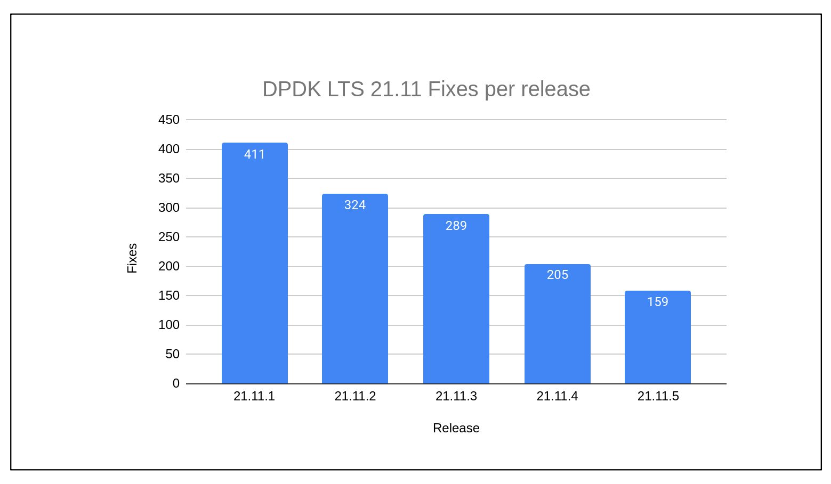
Longevity of LTS Maintenance
The question of why LTS releases are not maintained for extended periods, like 20 years, is addressed by the trend of diminishing fixes over time. As LTS versions become more stable, the need for frequent fixes decreases, justifying the typical LTS support duration.
Future Code Integrations and Impact on LTS
Looking ahead, future code integrations in DPDK may not significantly impact LTS releases. While library fixes might increase, the core stability of LTS releases is expected to be maintained.
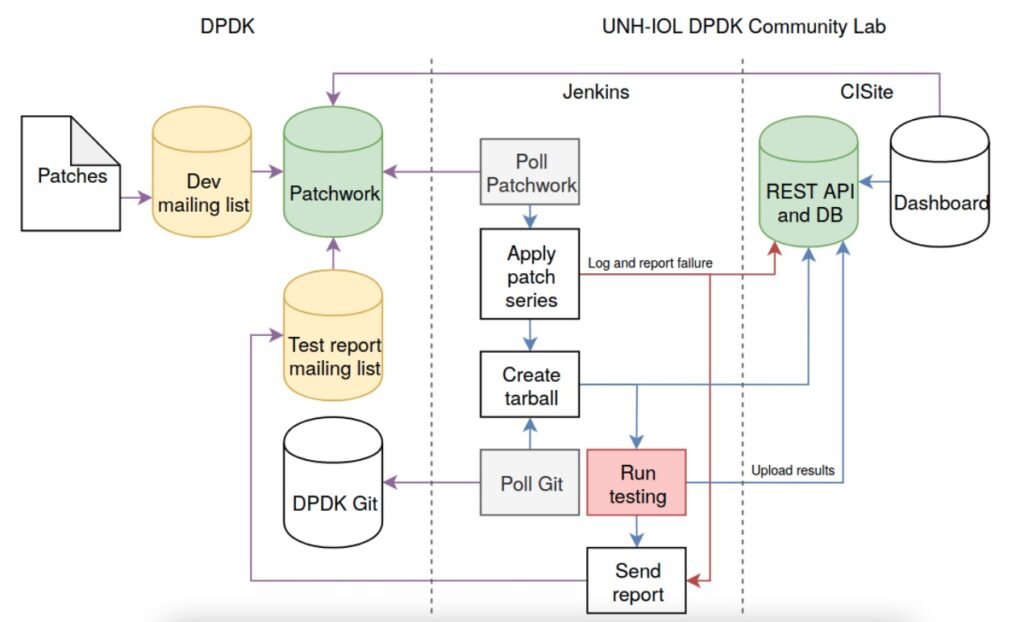
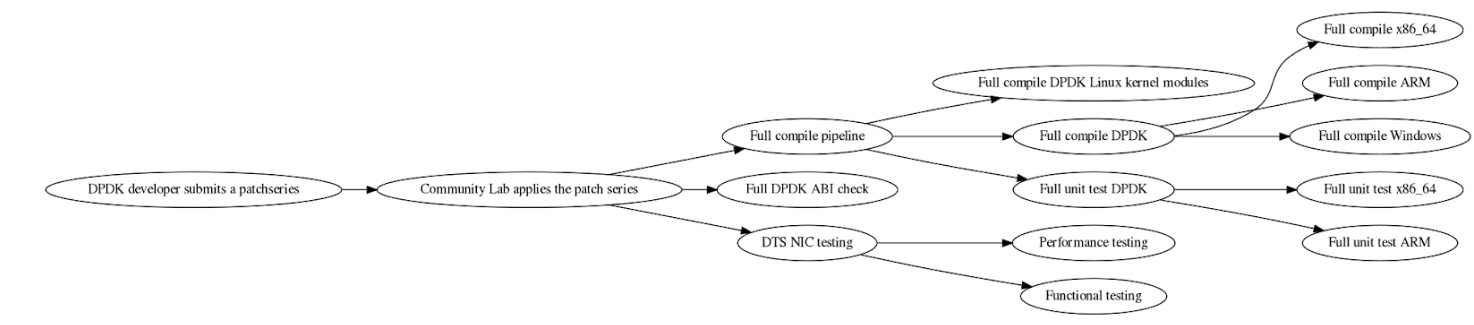
The Process Behind DPDK LTS Releases
The philosophy guiding LTS maintenance encapsulates a straightforward principle: “Don’t make it worse.” Key aspects of this philosophy include:
LTS Selection: Annually, one DPDK release is chosen to become an LTS version. Typically this is the November DPDK release. This release ceases to receive new features but is maintained to address critical issues.
Maintenance Workflow: Fixes from subsequent releases are ported back to the LTS release. For instance, if a significant bug is fixed in a March release, that fix is usually also applied to the LTS version.
Vendor Contributions: Updates for drivers specific to various hardware vendors are included in LTS releases, ensuring that common components remain stable across different platforms.
Validation: LTS releases are validated through a mix of CI and vendors dedicating validation resources.
Distribution Adoption: Prominent Linux distributions such as Red Hat, Ubuntu and Debian favor LTS releases due to their longer support window and relative feature stability.
The Role of LTS in Upstream Maintenance
The DPDK upstream maintainers are committed to ensuring that LTS releases receive the necessary fixes without introducing new issues. This careful balance underscores their dedication to the core LTS premise.
Statistical analysis of LTS releases provides insight into several key areas:
Fixes: The quantity and significance of the bug fixes an LTS release receives.
Bug Age: The duration that bugs existed before being fixed, indicating the codebase’s stability.
Code Areas: The sections of code that were most frequently fixed, highlighting areas of potential vulnerability or critical importance.
Why Opt for DPDK LTS?
Opting for a DPDK LTS release over a standard one is akin to choosing a well-established airline for travel—while it may not boast the newest features, its track record for safety is impeccable.
Industry Adoption
Companies like Red Hat and Ubuntu use LTS releases because they trust the extended support period will provide a stable foundation for their network infrastructure. This trust stems from the methodical maintenance and broad community endorsement of LTS releases, which adds another layer of testing and quality assurance.
Community and Self-Support
While LTS releases are backed by community support, there is nothing to prevent organizations from taking on their support initiatives. For example, if a company needs to support a particular network card with custom features, they can take an LTS release and integrate their changes while still benefiting from the core stability that LTS provides.
Update Overhead
LTS offers flexibility of when to update to the next LTS. If a new feature of interest is available in the next LTS then it can be worth the effort to update and also extend the longevity of using a maintained release.
If not, then it is fine to skip and wait for a later LTS. Staying with an LTS series means less effort to get fixes. It also means API/ABI compatibility, so there are no application code changes needed and less frequent product integration testing.
What if there’s a new interesting feature that is not yet in an LTS release yet? With one LTS released per year, there is always another one coming soon.
Example Integration into Other Projects
Open source projects like Open vSwitch (OVS) integrate DPDK LTS to enhance their performance. Each year the OVS project takes the newest DPDK LTS and integrates into their next release. This means that OVS users benefit from fixes and stability in the underlying DPDK drivers that it uses.
Which LTS Release Should You Pick?
The choice of the right DPDK LTS release hinges on various factors:
Support Window: Assess the duration of support your deployment requires.
Feature Set: Determine whether the LTS release contains the necessary features for your network applications, keeping in mind that it takes time for new features to become stable.
Vendor Compatibility: Check if the LTS release supports your hardware and if vendor-specific drivers are maintained.
Preparing for Transition: From LTS to LTS
Transitioning from one LTS release to the next requires careful planning. As exemplified by maintainers like Kevin Traynor in the 21.11 release, the process is detailed but manageable. Organizations should:
- Stay informed about the DPDK stable release schedule and plan their updates accordingly.
- Dedicate time to comprehensive testing when updating versions.
- Anticipate and prepare to address possible integration issues.
The Future of DPDK LTS Releases
Looking forward, DPDK LTS releases will continue to be a cornerstone for networks that value stability. The DPDK community, in conjunction with hardware vendors, is committed to ensuring that LTS releases are equipped to handle the demands of modern networking environments.
As we navigate this terrain, the feedback loop between users and maintainers will remain vital. Each fix, each update, and each LTS release is a product of collective effort and shared knowledge.
Call to Action: Join the Effort
As the DPDK LTS ecosystem thrives, we extend an open invitation to more companies and contributors to provide their input and expertise. Whether you’re a hardware vendor with an eye on driver optimizations or an enterprise leveraging DPDK for high-performance networking, your experiences and contributions are invaluable. The strength of an LTS release is not just in its code—it’s in the community that molds and shapes it.
Learn more about DPDK LTS releases here