By Honnappa Nagarahalli
As an increasingly higher number of cores are packed together in a SoC, thread synchronization plays a key role in scalability of the application. In the context of networking applications, because of the partitioning of the application into control plane (write-mostly threads) and data plane (read-mostly threads), reader-writer concurrency is a frequently encountered thread synchronization use case. Without an effective solution for reader-writer concurrency, the application will end up with:
- race conditions, which are hard to solve
- unnecessary/excessive validations in the reader, resulting in degraded performance • excessive use of memory barriers, affecting the performance
- and, finally, code that is hard to understand and maintain
In this blog, I will
- briefly introduce the reader-writer concurrency problem
- talk about solving reader-writer concurrency using full memory barriers and the C11 memory model
- and, talk about complex scenarios that exist
Problem Statement
Consider two or more threads or processes sharing memory. Writer threads/processes (writers) update a data structure in shared memory in order to convey information to readers. Reader threads/processes (readers) read the same data structure to carry out some action. E.g.: in the context of a networking application, the writer could be a control plane thread writing to a hash table, the reader could be a data plane thread performing lookups in the hash table to identify an action to take on a packet.
Essentially, the writer wants to communicate some data to the reader. It must be done such that the reader observes the data consistently and atomically instead of observing an incomplete or intermediate state of data.
This problem can easily be solved using a reader-writer lock. But locks have scalability problems, and a lock free solution is required so that performance scales linearly with the number of readers.
Solution
In order to communicate the ‘data’ atomically, a ‘guard variable’ can be used. Consider the following diagram.
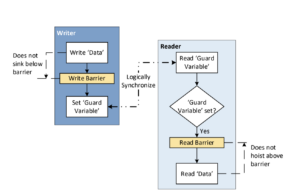
The writer sets the guard variable atomically after it writes the data. The write barrier between the two ensures that the store to data completes before the store to guard variable.
The reader reads the guard variable atomically and checks if it is set. If it is set, indicating that the writer has completed writing data, the reader can read the data. The read barrier between the two ensures that the load of data starts only after the guard variable has been loaded. i.e. the reader is prevented from reading data (speculatively or due to reordering) till the guard variable is set. There is no need for any additional validations in the reader.
As shown, the writer and the reader synchronize with each other using the guard variable. The use of the guard variable ensures that the data is available to the reader atomically irrespective of the size of the data. There is no need of any additional barriers in the writer or the reader.
Some of the CPU architectures enforce the program order for memory operations in the writer and the reader without the need for explicit barriers. However, since the compiler can introduce re-ordering, the compiler barriers are required on such architectures.
So, when working on a reader-writer concurrency use-case, the first step is to identify the ‘data’ and the ‘guard variable’.
Solving reader-writer concurrency using C11 memory model
In the above algorithm, the read and write barriers can be implemented as full barriers. However, full barriers are not necessary. The ordering needs to be enforced between the memory operations on the data (and other operations dependent on data) and the guard variable. Other independent memory operations need not be ordered with respect to memory operations on data or guard variable. This provides CPU micro-architectures more flexibility in re-ordering the operations while executing the code. C11 memory model allows for expressing such behaviors. In particular, C11 memory model allows for replacing the full barriers with one-way barriers.
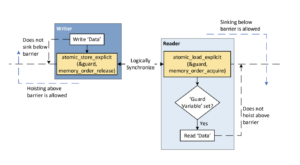
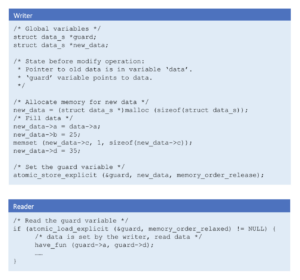
As shown above, the writer uses the atomic_store_explicit function with memory_order_release to set the guard variable. This ensures that the write to data completes before the write to guard variable completes while allowing for later memory operations to hoist above the barrier.
The reader uses the atomic_load_explicit function with memory_order_acquire to load the guard variable. This ensures that the load of the data starts only after the load of the guard variable completes while allowing for the earlier operations to sink below the barrier.
atomic_store_explicit and atomic_load_explicit functions ensure that the operations are atomic and enforce the required compiler barriers implicitly.
Challenges
The above paragraphs did not go into various details associated with data. The contents of data, support for atomic operations in the CPU architecture, and support for APIs to modify the data can present various challenges.
Size of data is more than the size of atomic operations
Consider data of the following structure.

The size of the data is 160 bits, which is more than the size of the atomic operations supported by the CPU architectures. In this case, the guard variable is required to communicate the data atomically to the reader.
If support required is for add API alone, the basic algorithm described in above paragraphs is sufficient. The following code shows the implementation of writer and reader.

However, several challenges exist if one wants to support an API to modify/update data depending on the total size of modifications.
Size of the modified elements is larger than the size of atomic operations
Let us consider the case when the total size of modifications is more than the size of atomic operations supported.
Since all modified elements of data need to be observed by the reader atomically, a new copy of the data needs to be created. This new copy can consist of a mix of modified and unmodified elements. The guard variable can be a pointer to data or any atomically modifiable variable used to derive the address of data, for ex: an index into an array. After the new copy is created, the writer updates the guard variable to point to the new data. This ensures that, the modified data is observed by the reader atomically.
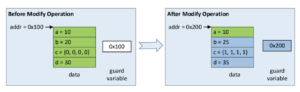
As shown above, the elements b, c and d need to be updated. Memory at addr 0x200 is allocated for the new copy of data. Element a is copied from the current data. Elements b, c and d are updated with new values in the new copy of data. The guard variable is updated with the new memory address 0x200. This ensures that the modifications of the elements b, c and d appear atomically to the reader.
In the reader, there is dependency between data and the guard variable as data cannot be loaded without loading the guard variable. Hence, the barrier between the load of the guard variable and data is not required. While using C11 memory model, memory_order_relaxed can be used to load the guard variable.
The following code shows the implementation of writer and reader.
Note that, the writer must ensure that all the readers have stopped referencing the memory containing the old data before freeing it.
Size of the modified elements is equal to the size of atomic operations
Now, consider the case when the total size of modifications is equal to the size of atomic operations supported.
Such modifications do not need a new copy of data as the atomic operations supported by the CPU architecture ensure that the updates are observed by the reader atomically. These updates must use atomic operations.
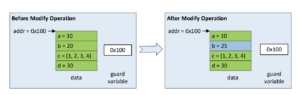
As shown above, if only element b has to be updated, it can be updated atomically without creating a new copy of data in the writer. The store and load operations in writer and reader do not require any barriers. memory_order_relaxed can be used with atomic_store_explicit and atomic_load_explicit functions.
Size of data is equal to the size of atomic operations
Consider a structure for data as follows

The size of the data is 64 bits. All modern CPU architectures support 64 bit atomic operations.
In this case, there is no need of a separate guard variable for both add and modify APIs. Atomic store of the data in writer and atomic load of the data in reader is sufficient. The store and load operations do not require any barrier in the writer or reader either. memory_order_relaxed can be used with both atomic_store_explicit and atomic_load_explicit functions. As shown above, if required, part of the data can indicate if it contains valid data.

Conclusion
So, whenever faced with a reader-writer synchronization issue, identify the data, consider if a guard variable is required. Keep in mind that what matters is the ordering of memory operations and not when the data is visible to the reader. Following the methods mentioned above will ensure that unnecessary barriers and validations are avoided, and the code is race free and optimized.